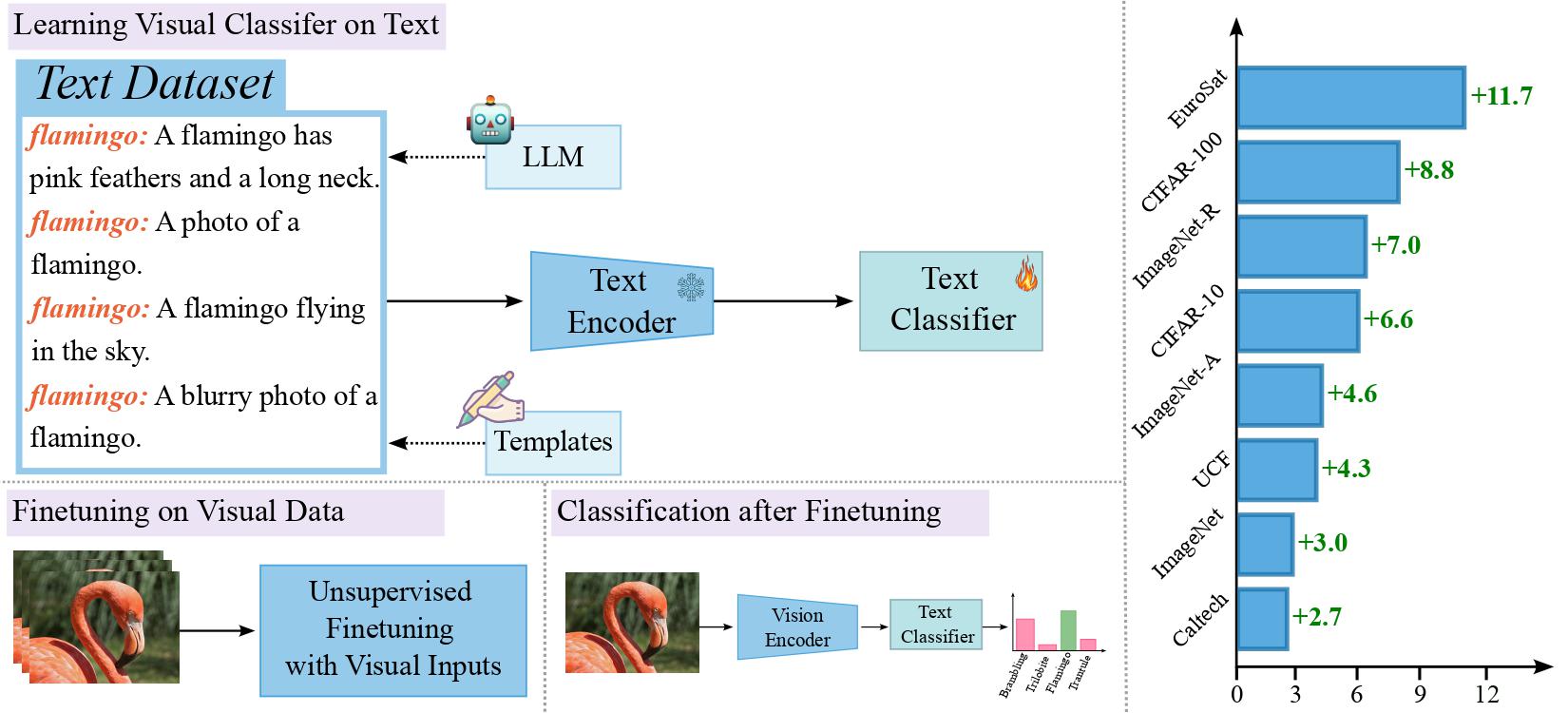
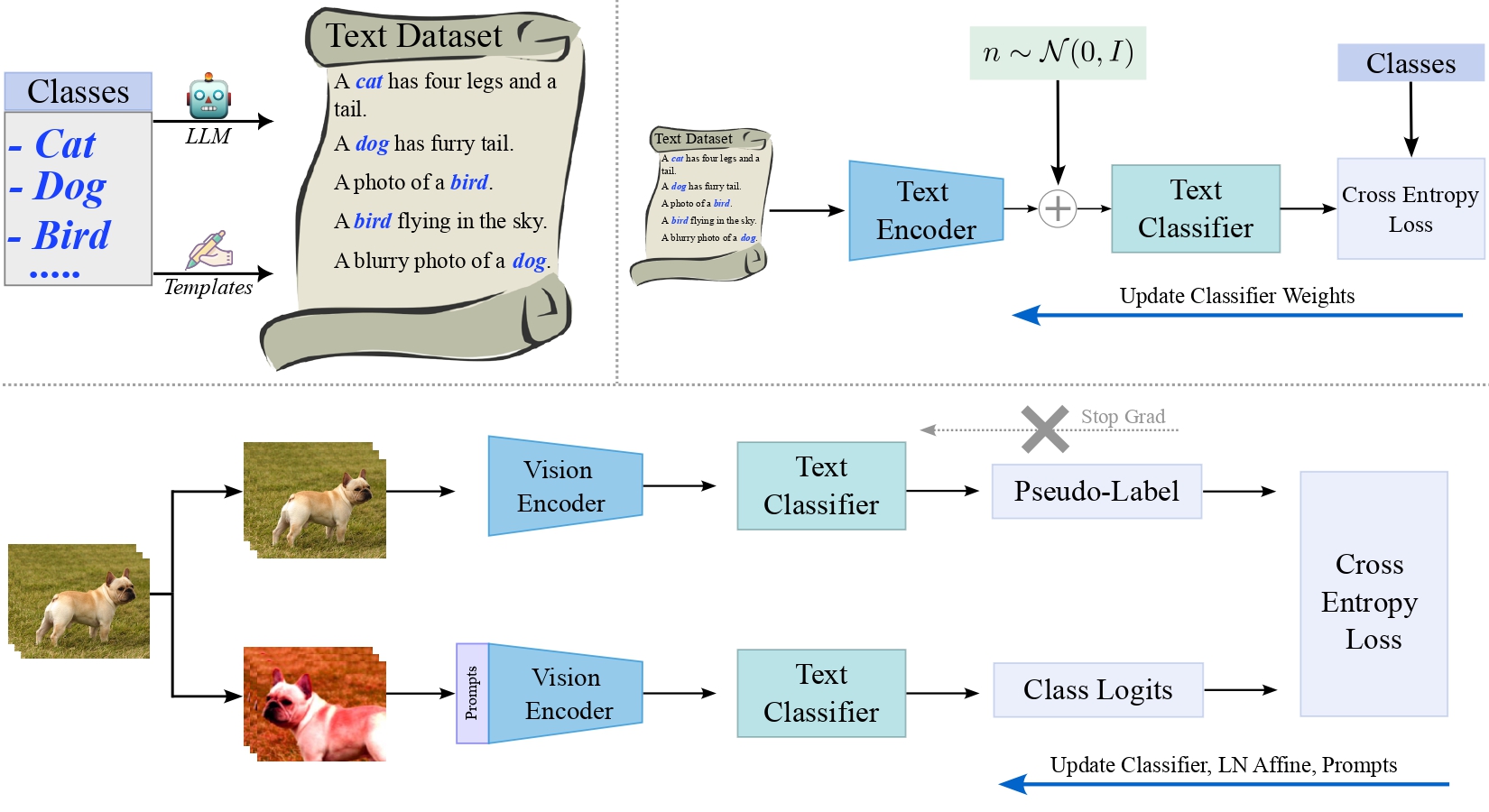
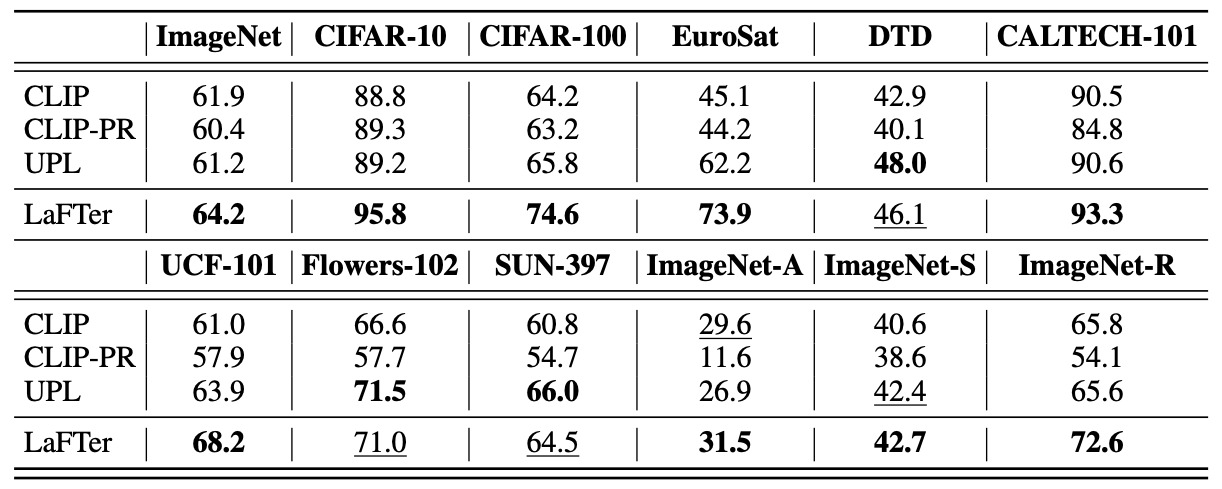
Recently, large-scale pre-trained Vision and Language (VL) models have set a new state-of-the-art (SOTA) in zero-shot visual classification enabling open-vocabulary recognition of potentially unlimited set of categories defined as simple language prompts. However, despite these great advances, the performance of these zeroshot classifiers still falls short of the results of dedicated (closed category set) classifiers trained with supervised fine-tuning. In this paper we show, for the first time, how to reduce this gap without any labels and without any paired VL data, using an unlabeled image collection and a set of texts auto-generated using a Large Language Model (LLM) describing the categories of interest and effectively substituting labeled visual instances of those categories. Using our label-free approach, we are able to attain significant performance improvements over the zero-shot performance of the base VL model and other contemporary methods and baselines on a wide variety of datasets, demonstrating absolute improvement of up to 11.7% (3.8% on average) in the label-free setting. Moreover, despite our approach being label-free, we observe 1.3% average gains over leading few-shot prompting baselines that do use 5-shot supervision.
@InProceedings{mirza2023lafter,
author = {Mirza, M. Jehanzeb and Karlinsky, Leonid and Lin, Wei and Kozinski, Mateusz and
Possegger, Horst and Feris, Rogerio and Bischof, Horst},
title = {LaFTer: Label-Free Tuning of Zero-shot Classifier using Language and Unlabeled Image Collections},
booktitle = {Conference on Neural Information Processing Systems (NeurIPS)},
year = {2023}
}