Jehanzeb Mirza
Agentic AI | Multimodal Reasoning | Test-Time Learning
Xero, USA | Formerly MIT CSAIL






Hi, I am Jehanzeb Mirza. I am a Staff Research Scientist at Xero, where I build agentic AI systems for financial applications (tool use, structured reasoning, evaluation, and optimization). Previously, I was a Postdoctoral Researcher at MIT CSAIL in the Spoken Language Systems Group led by Dr. James Glass. I received my Ph.D. in Computer Science (Computer Vision) from TU Graz, Austria, where I was advised by Professor Horst Bischof, and Professor Serge Belongie served as an external referee.
My research spans multimodal foundation models (vision, language, audio) and test-time learning, with an emphasis on robust reasoning and decision-making. I am particularly interested in building reliable AI agents that can interface with tools and operate over complex structured data.
Outside of work, I enjoy traveling, running, and playing squash. I currently take squash lessons from former World No. 1 Thierry Lincou.
Selected work has been featured by MIT News and CSAIL research spotlights. I’m always happy to connect with student collaborators and researchers working on multimodal learning, LLM/VLM reasoning, and agentic systems—feel free to email me for feedback or collaboration.
Contact
- jmirza [at] mit.edu
- Office: 32-G442.
- MIT, Cambridge, USA.
Education
-
Ph.D. in Computer Vision (2021 - 2024)
TU Graz, Austria. -
MS in ETIT (2017 - 2020)
KIT, Germany. -
BS in EE (2013 - 2017)
NUST, Pakistan
Recent News
Experience
Selected Publications
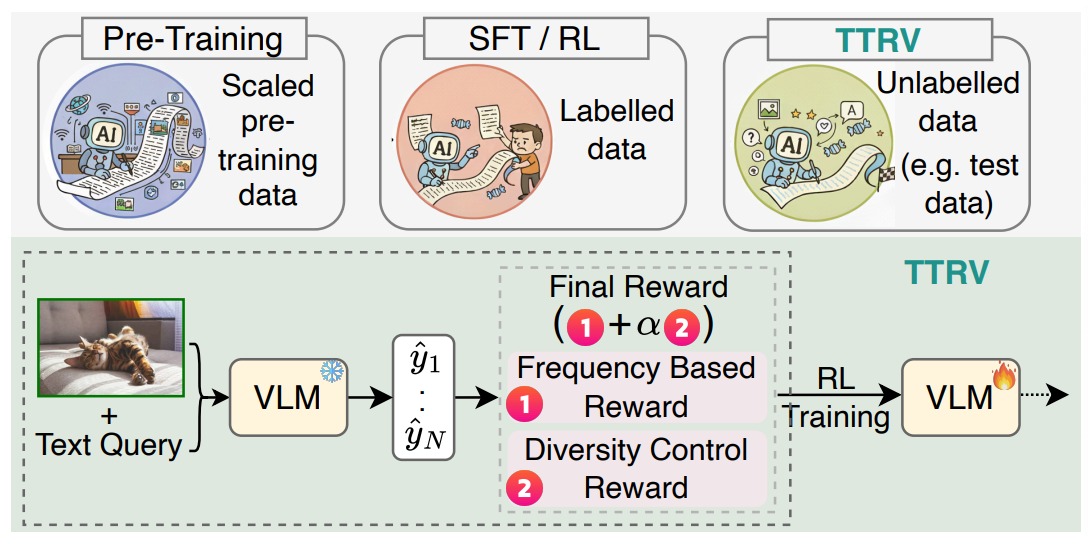
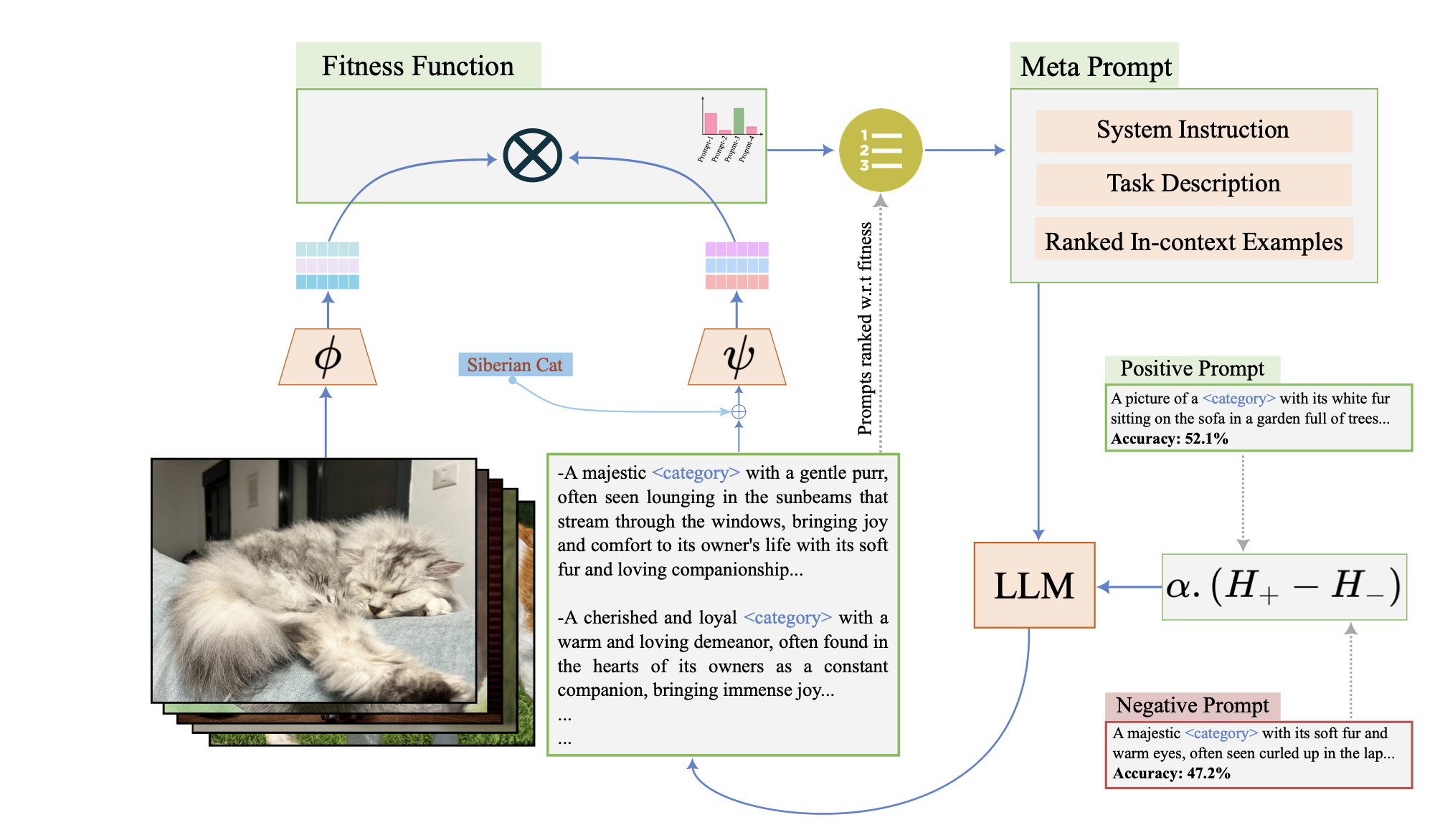
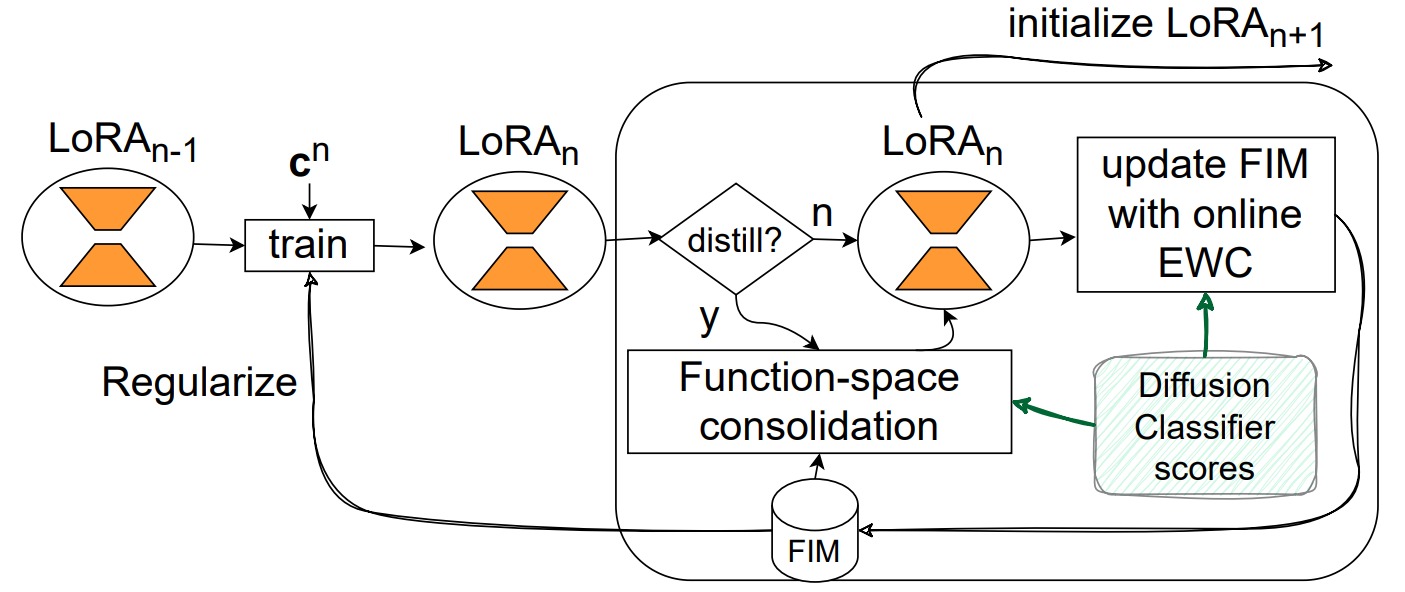
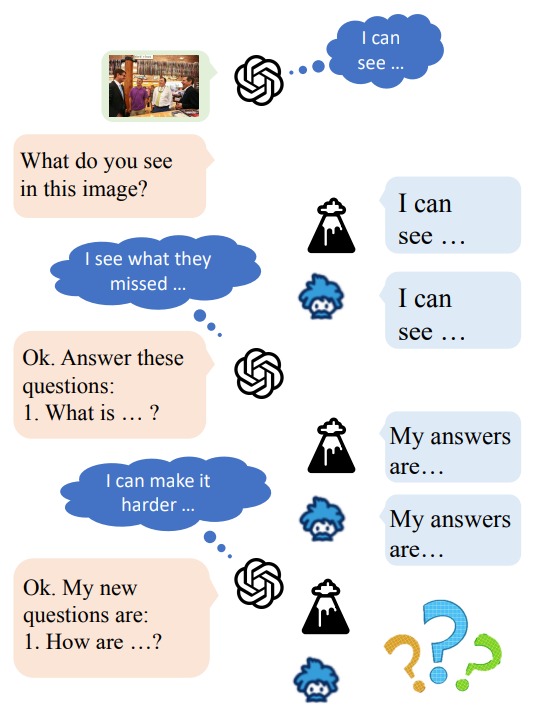
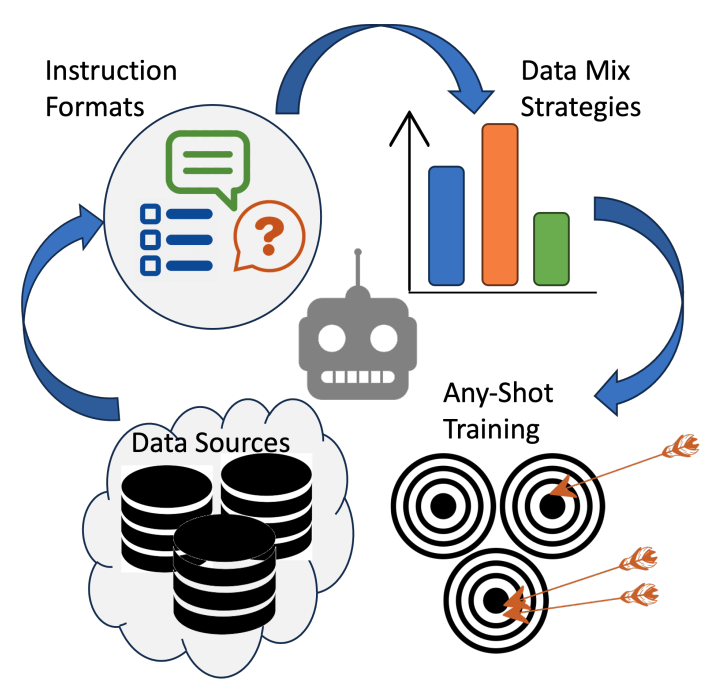
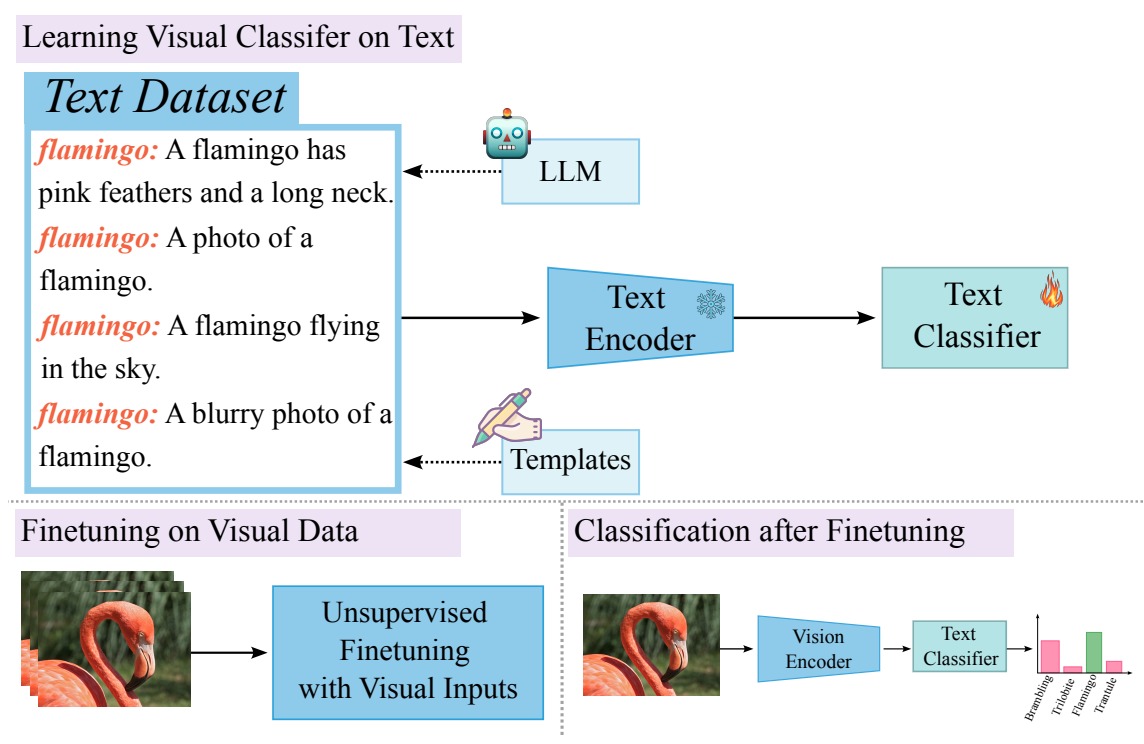
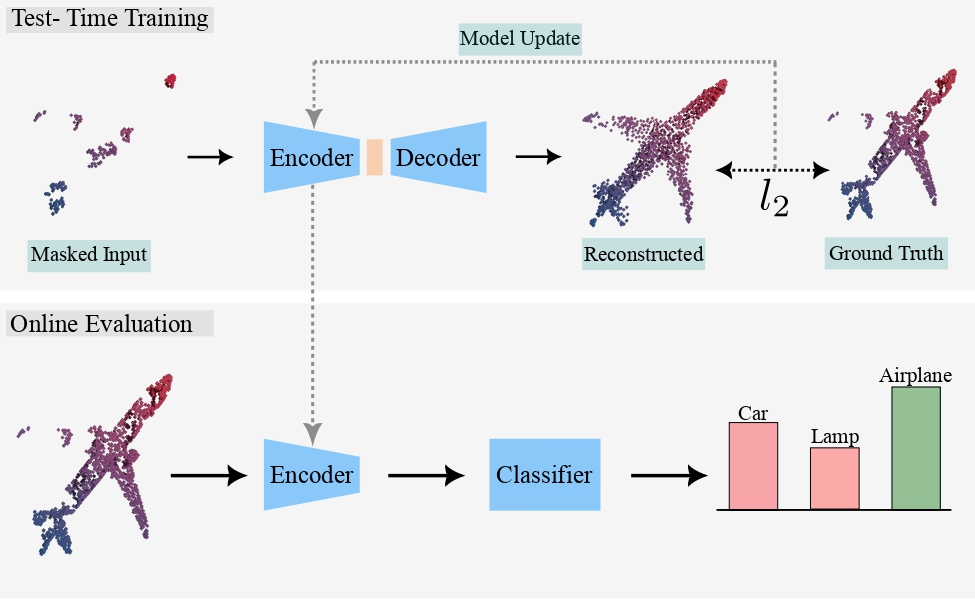
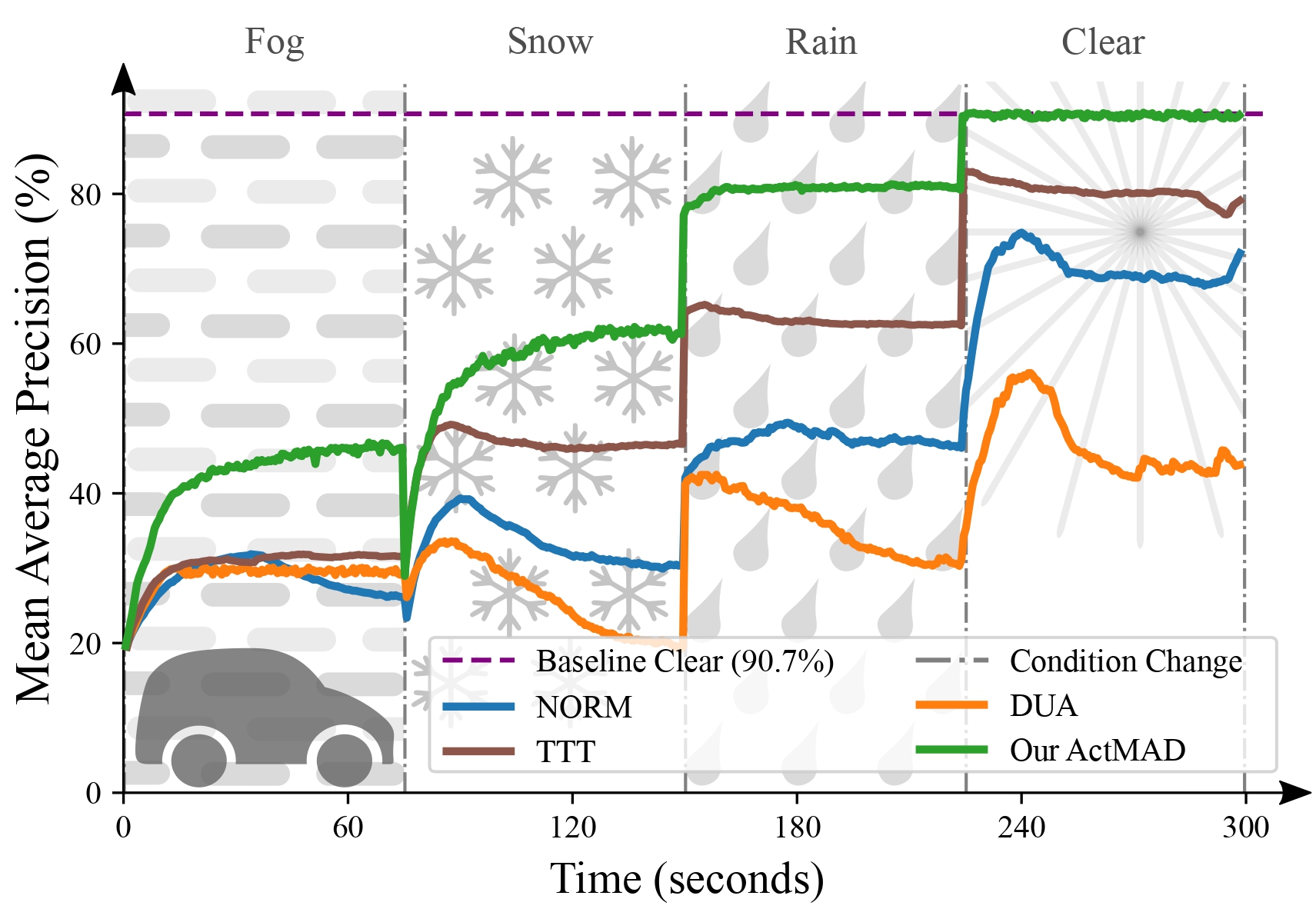
Test-time reinforcement learning strategy for improving VLM reasoning and decision quality.

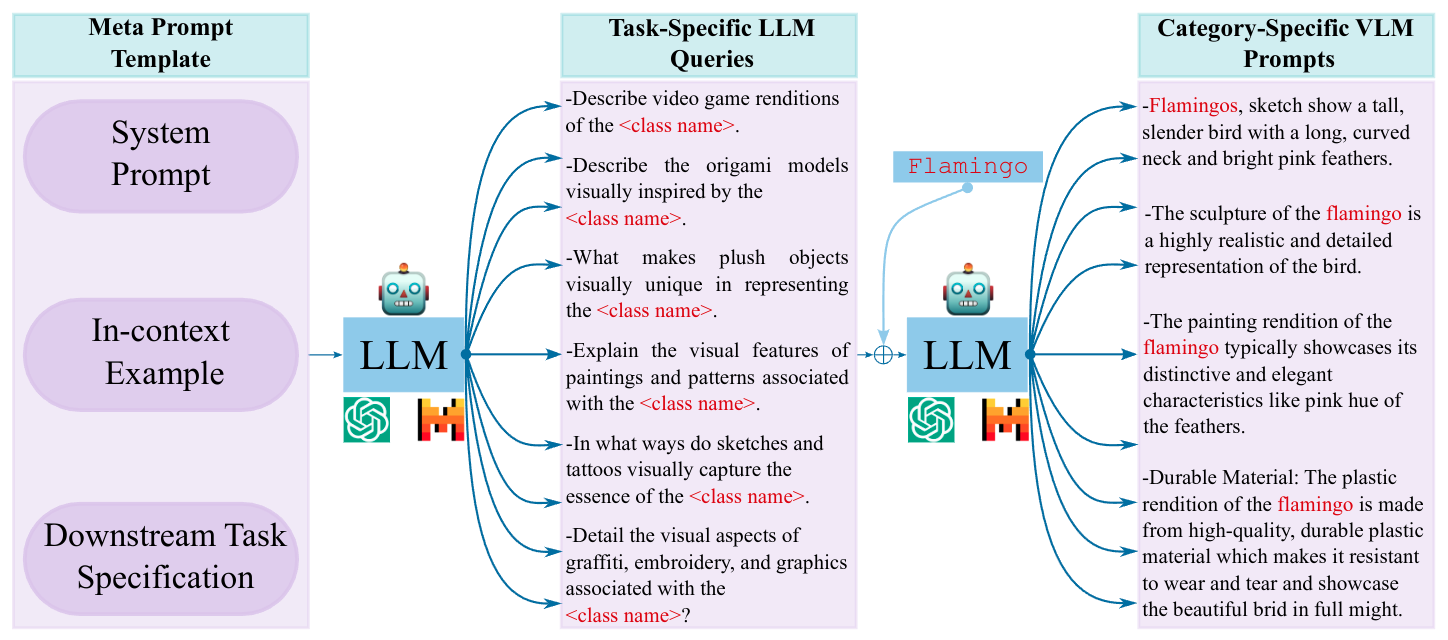
Teaching VLMs to localize specific objects from in-context examples for fine-grained grounding.
No publications match this combination.