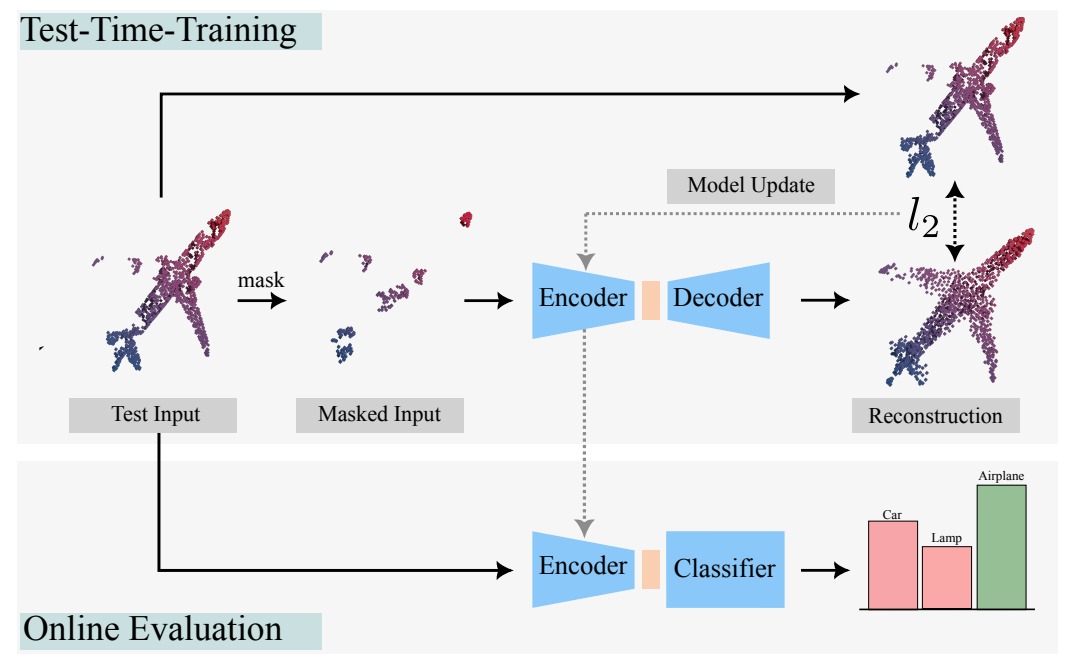
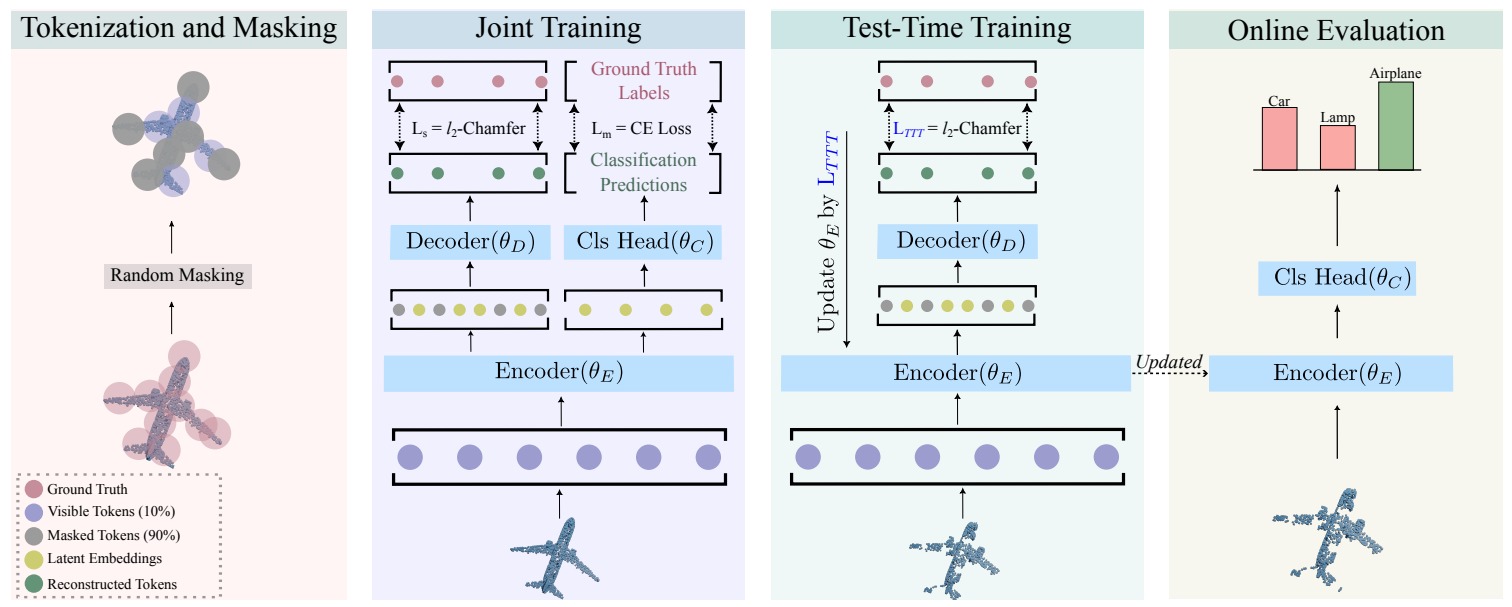
Our MATE is the first Test-Time-Training (TTT) method designed for 3D data, which makes deep networks trained for point cloud classification robust to distribution shifts occurring in test data. Like existing TTT methods from the 2D image domain, MATE also leverages test data for adaptation. Its test-time objective is that of a Masked Autoencoder: a large portion of each test point cloud is removed before it is fed to the network, tasked with reconstructing the full point cloud. Once the network is updated, it is used to classify the point cloud. We test MATE on several 3D object classification datasets and show that it significantly improves robustness of deep networks to several types of corruptions commonly occurring in 3D point clouds. We show that MATE is very efficient in terms of the fraction of points it needs for the adaptation. It can effectively adapt given as few as 5% of tokens of each test sample, making it extremely lightweight. Our experiments show that MATE also achieves competitive performance by adapting sparsely on the test data, which further reduces its computational overhead, making it ideal for real-time applications.

@article{mirza2023mate,
author = {Mirza, M. Jehanzeb and Shin, Inkyu and Lin, Wei and Schriebl, Andreas and Sun, Kunyang and
Choe, Jaesung and Kozinski, Mateusz and Possegger, Horst and Kweon, In So and Yoon, Kun-Jin and Bischof, Horst},
title = {MATE: Masked Autoencoders are Online 3D Test-Time Learners},
journal = {arXiv preprint arXiv:2211.11432},
year = {2023}
}