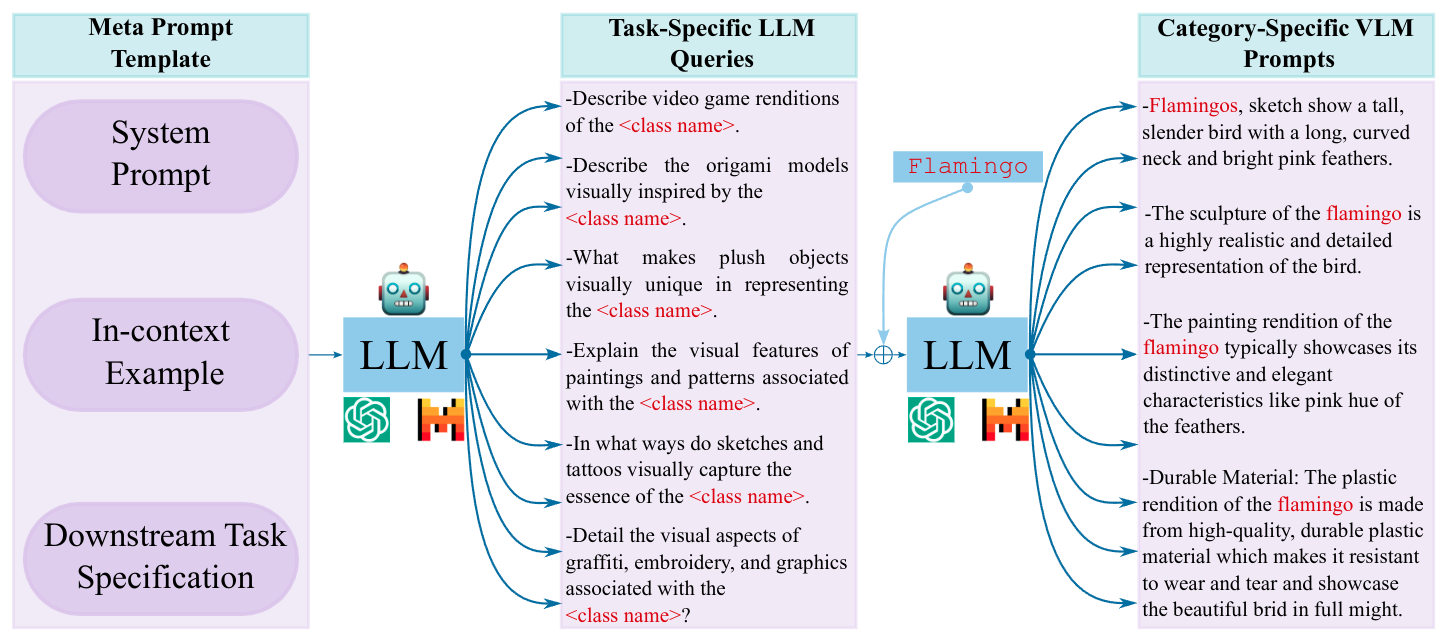
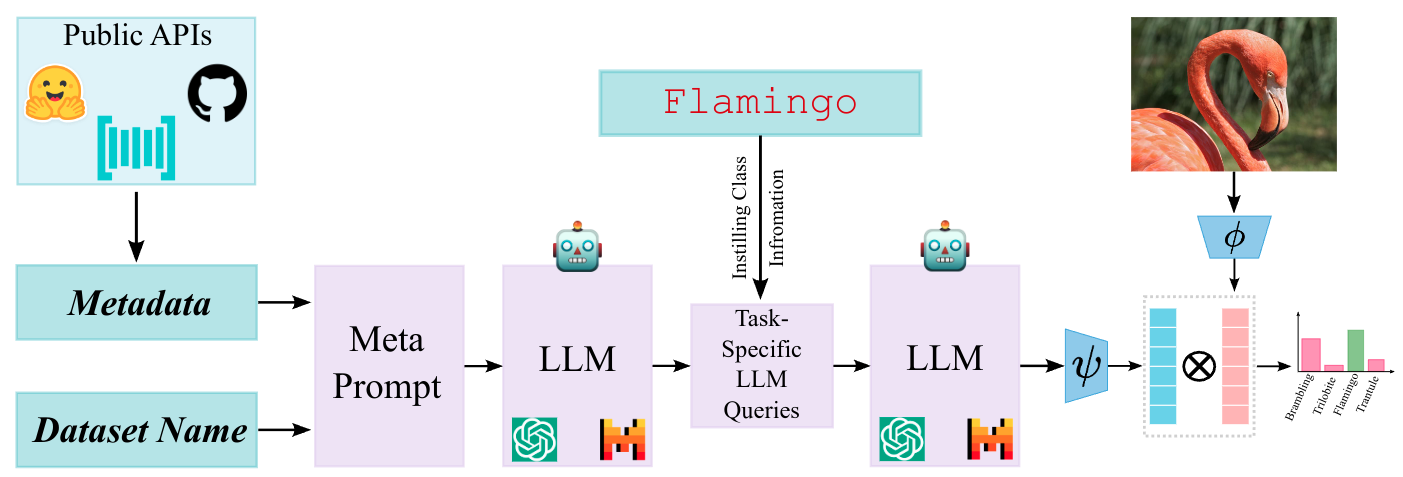
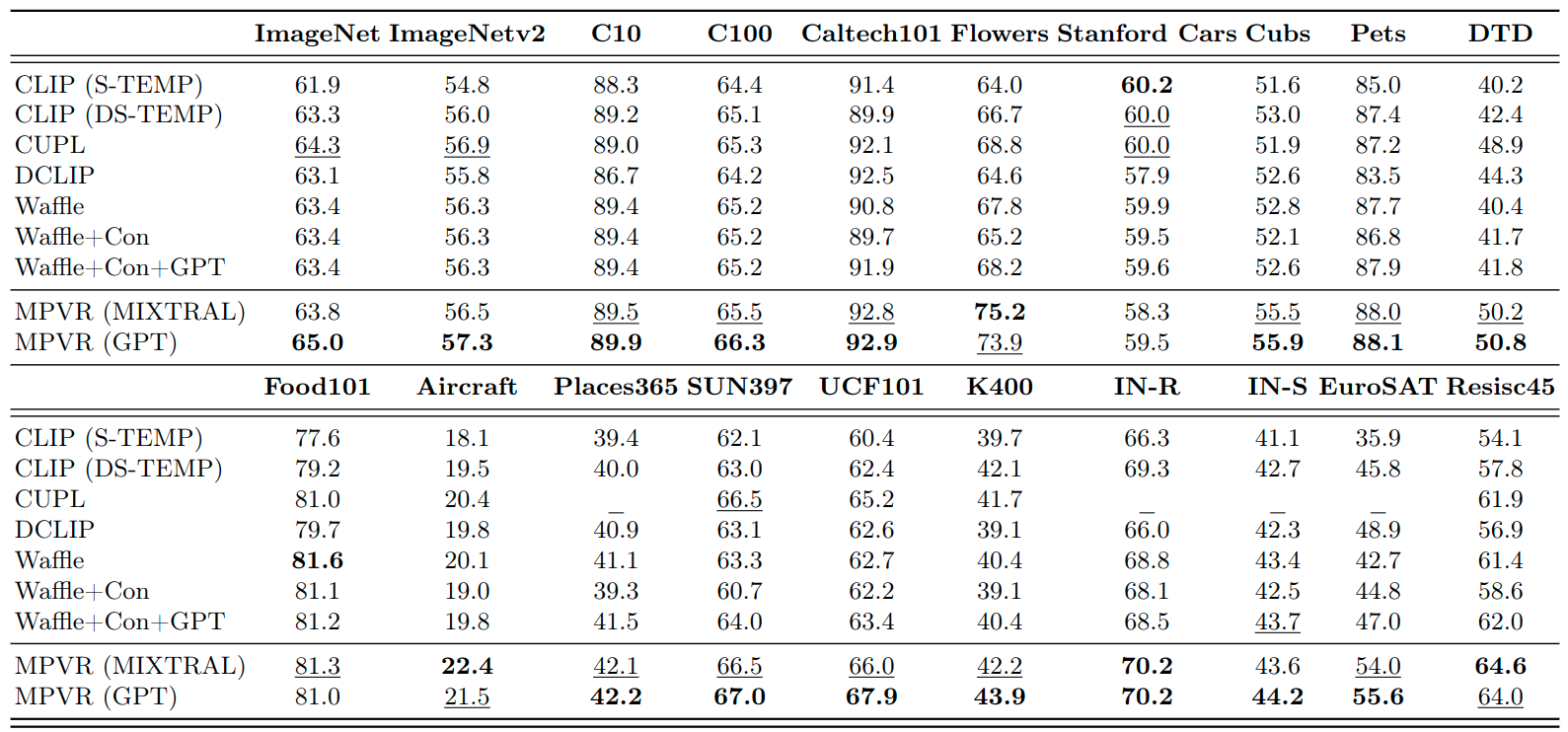
Prompt ensembling of Large Language Model (LLM) generated category-specific prompts has emerged as an effective method to enhance zero-shot recognition ability of Vision-Language Models (VLMs). To obtain these category-specific prompts, the present methods rely on hand-crafting the prompts to the LLMs for generating VLM prompts for the downstream tasks. However, this requires manually composing these task-specific prompts and still, they might not cover the diverse set of visual concepts and task-specific styles associated with the categories of interest. To effectively take humans out of the loop and completely automate the prompt generation process for zero-shot recognition, we propose Meta-Prompting for Visual Recognition (MPVR). Taking as input only minimal information about the target task, in the form of its short natural language description, and a list of associated class labels, MPVR automatically produces a diverse set of category-specific prompts resulting in a strong zero-shot classifier. MPVR generalizes effectively across various popular zero-shot image recognition benchmarks belonging to widely different domains when tested with multiple LLMs and VLMs. For example, MPVR obtains a zero-shot recognition improvement over CLIP by up to 19.8% and 18.2% (5.0% and 4.5% on average over 20 datasets) leveraging GPT and Mixtral LLMs.
@article{mirza2023mpvr,
author = {Mirza, M. Jehanzeb and Karlinsky, Leonid and Lin, Wei and Doveh, Sivan and
and Micorek, Jakub and Kozinski, Mateusz and Kuhene, Hilde and Possegger, Horst},
journal = {ArXiv},
title = {{Meta-Prompting for Automating Zero-shot Visual Recognition with LLMs}},
year = {2024}
}